Prof. Douglas Thain at Notre Dame
Blog: Fail Fast, Fail Often
08 Feb 2009 - Douglas Thain
A common misconception among programmers is that software should always attempt to hide failures in distributed systems. This idea seems sensible at first, because distributed systems are full of failures of all kinds: machines crash, software fails, and networks go down, just to name a few. If I am writing a function called transfer_file() which copies a file from one place to another, then I should try to connect multiple times and restart failed transfers for about an hour before giving up, right?It turns out that transparent fault tolerance is exactly the wrong approach in a large, layered software system. Instead, each layer of software should carefully define consistent failure conditions, and then feel free to fail as often as it wants to.
Here is why: If someone else builds an application that calls transfer_file() , the application itself knows a whole lot more about what kind of fault tolerance is needed. It may turn out that the application knows about several file servers, and if one cannot be reached immediately, then another will do just fine. On the other hand, perhaps transfer_file will be used in some batch workload that will run for weeks, so it is vital that the transfer be retried until success.
If you want to build a controllable system, then your building blocks must have very precise failure semantics.. Unfortunately, many system calls have such vague semantics that they are nearly impossible to use correctly in the presence of failures. Consider, for example, the Unix system call connect(), which initiates a TCP connection to a remote host. Here are some possible results from connect():
- If the host does not respond to IP traffic, connect() will block for an undetermined amount of time configured by the kernel (anywhere from minutes to hours), and then return ETIMEDOUT.
- If a router or switch determines that the host is not routable, then in a few seconds connect() will return with the error EHOSTUNREACH.
- If the host is up, but there is no process listening on the port, then connect() will return almost immediately with ECONNREFUSED.
Depending on the precise nature of the failure, the call might return immediately, or it might return after a few hours. And, the distinction between these failure modes hardly matters to the user: in each case, the requested service is simply not available. Imagine trying to build an application that will quickly connect to the first available server, out of three. Yuck.
To get around this, all our software uses an intermediate layer that does a fair amount of work to place consistent failure semantics on system calls. For example, instead of using BSD sockets directly, we have a layer called link with operations like this:
- link_connect( address, port, timeout );
- link_accept( link, timeout );
- link_read( link, buffer, length, timeout );
Inside each of these operations, the library carefully implements the desired failure semantics. If an operation fails quickly, then it is retried (with an exponential backoff) until the timeout as expired. If an operation fails slowly, then it is cleanly aborted when the timeout expires. With these in place, we can build higher level operations that rely on network communication without getting unexpectedly stuck.
Here is an example where precise failure detection really matters. In an earlier post, I wrote about the Wavefront abstraction , which is a distributed computing model with a lot of dependencies. In a Wavefront problem, we must first execute one process in the lower left hand corner. Once that is complete, we can run two adjacent functions, then three, and so on:
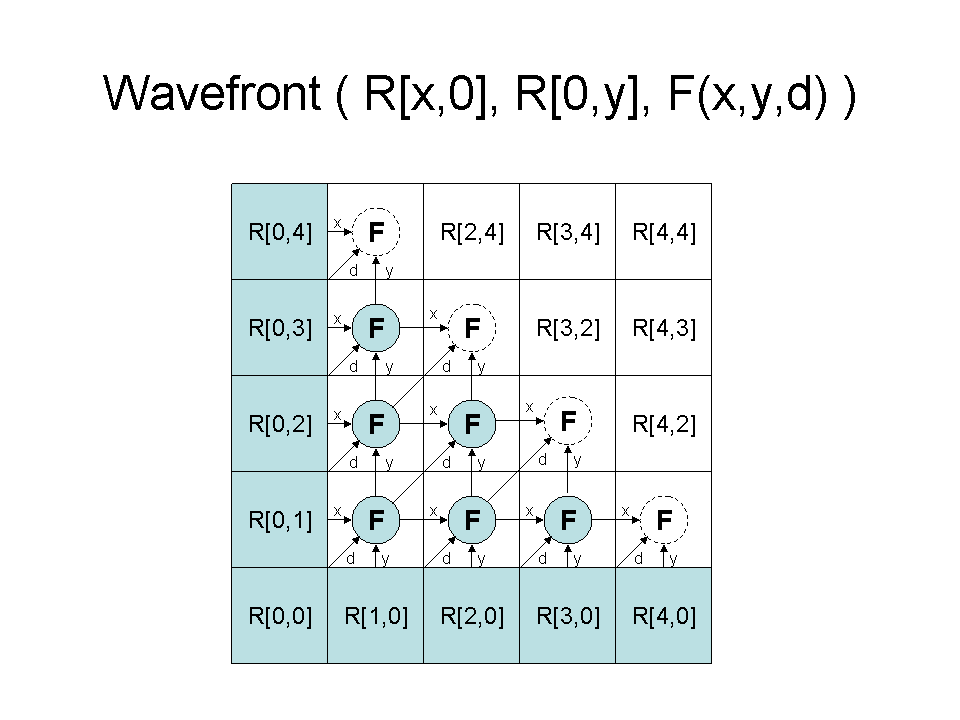
If we run a Wavefront on a system of hundreds of processors, then delays are inevitable. What's more, a delay in the computation of any one result slows down the whole system. To avoid this problem, we keep running statistics on the expected computation time of any node, and set timeouts appropriately. If any one computation falls more than a few standard deviations beyond the average, we abort it and try it on another processor. We call this technique "Fast Abort".
Here is the effect of this technique on a large wavefront problem. The X axis shows time, and the Y axis shows the number of tasks currently running. The bottom line shows the reliable technique of waiting and retrying tasks until they succeed. The top line shows what happens with Fast Abort. As you can see, this technique much more rapidly reaches a high degree of parallelism.
 The moral of the story is:
Make failure conditions an explicit part of your interface.
If you make it very clear how and when a call can fail, then it is very easy for applications to implement fault tolerance appropriate to the situation at hand.
The moral of the story is:
Make failure conditions an explicit part of your interface.
If you make it very clear how and when a call can fail, then it is very easy for applications to implement fault tolerance appropriate to the situation at hand.